GenAI 如今非常流行。这并不是一件坏事,大型语言模型 (LLM) 已经在扰乱营销和电子商务。但人工智能还有其他方法可以提高营销成果,这些方法更快、更容易,最重要的是更便宜。在本文中,我们将介绍改善营销成果的 10 种技术。
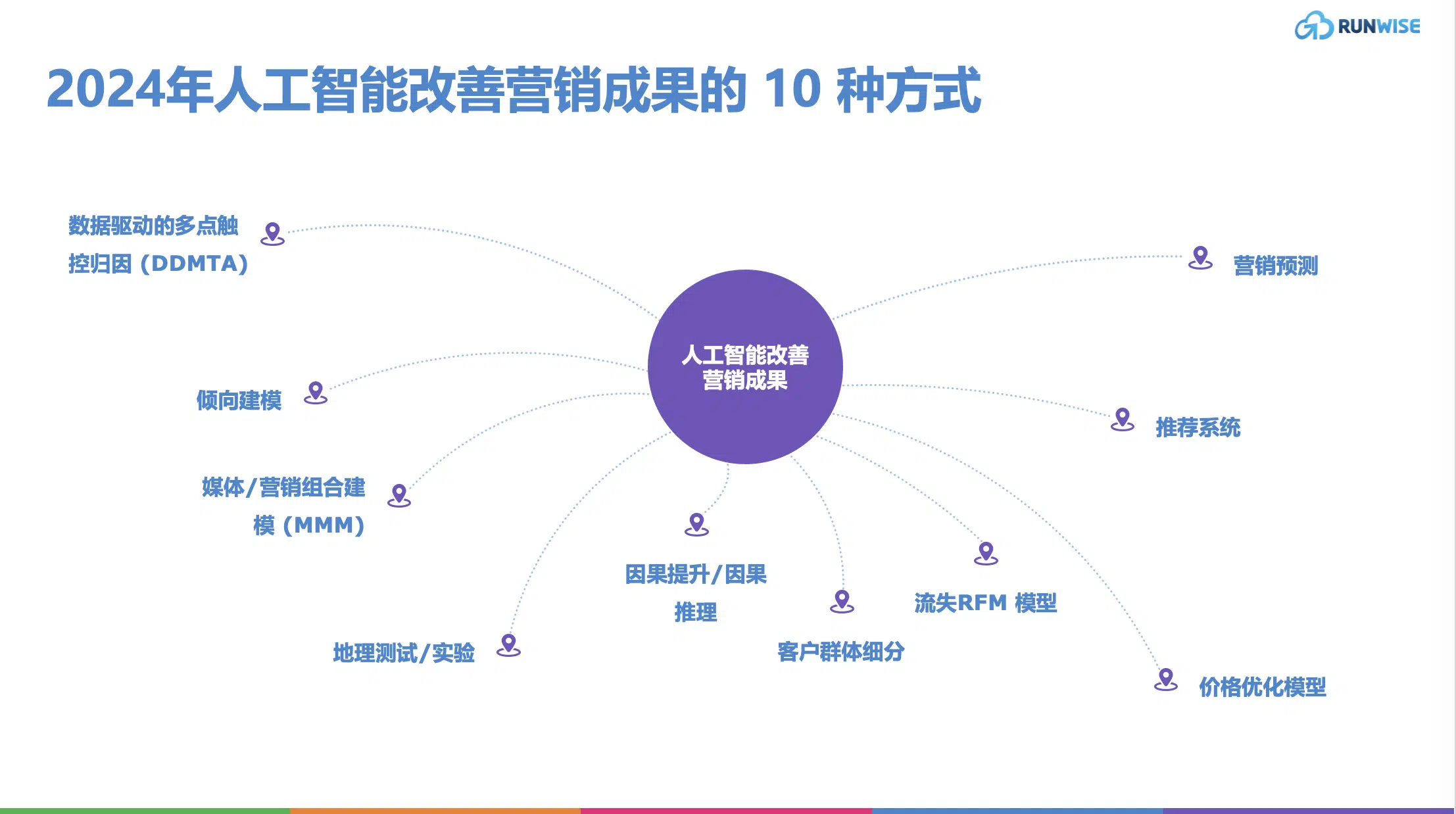
01. 数据驱动的多点触控归因 (DDMTA)
人们普遍认为“关于我的死亡的报道被严重夸大了”,但它也可以很容易地应用于多点触控归因,尽管有新的隐私控制,但它仍然非常活跃,并且继续高度表明数字营销效果的有效性。
虽然启发式测量通常是一个很好的指标,但更多数据驱动的方法可以将 MTA 提升到一个新的水平。最受欢迎的三个是:
- 马尔可夫链(概率)
- 匀称的价值观(博弈论)
- 附加危险(生存分析)
其中每一个都以不同的方式应对 MTA 挑战。马尔可夫使用概率,Shapely 使用博弈论,加性风险是解释客户接触点之间时间段的唯一模型。
为我们的客户实施这些后,我们发现马尔可夫模型重视渠道团队的合作以推动转化,而生存分析模型则倾向于更快的转化,因为它考虑到了时间。
揭示这些类型的见解可以更好地评估渠道绩效,从而改善支出优化。
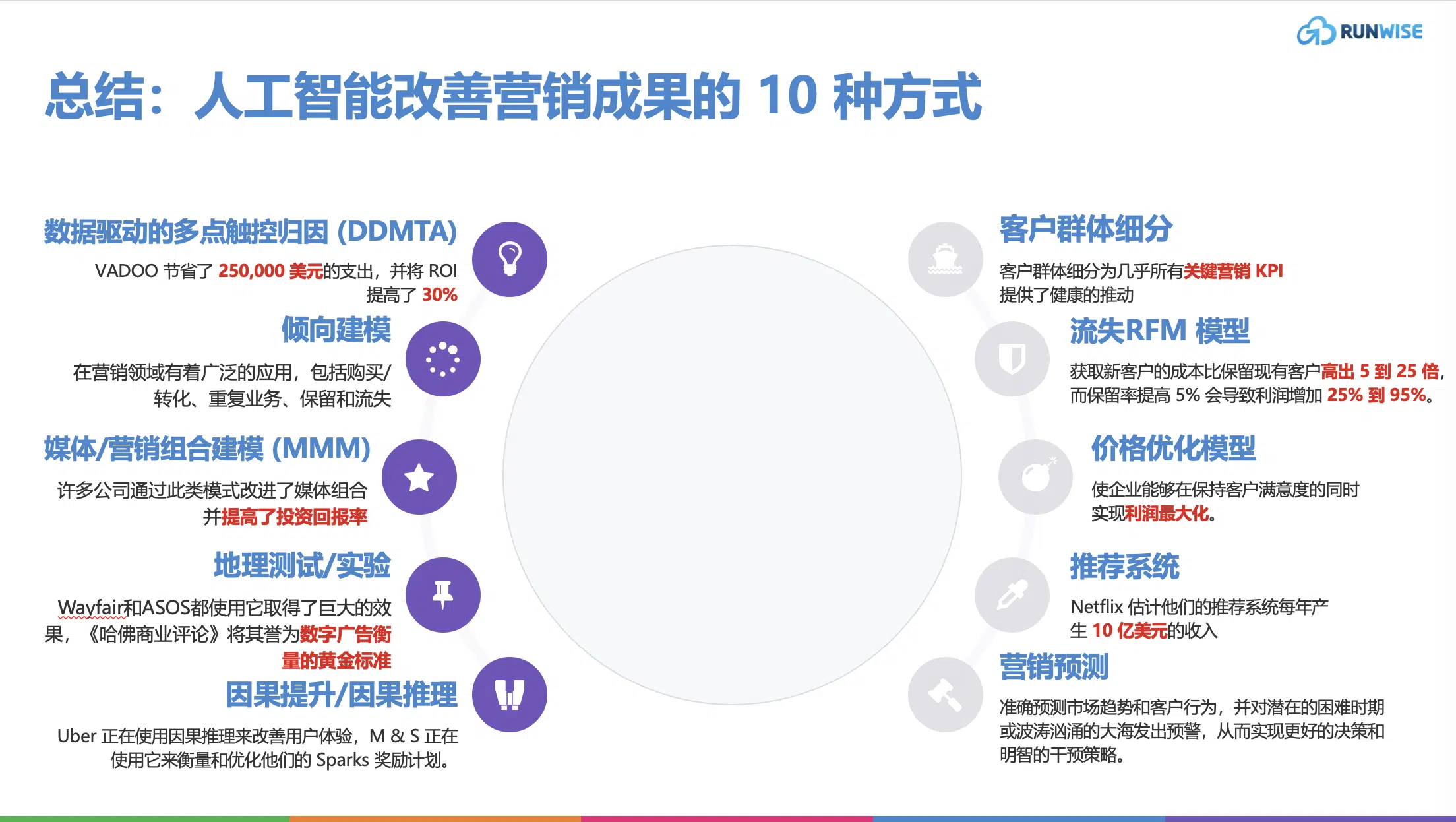
有大量证据表明,数据驱动 MTA 为 Lenovo 带来了诸多好处,从根本上改善了他们对跨渠道效率的看法,而AVADOO 节省了 250,000 美元的支出,并将 ROI 提高了 30%。
02. 倾向建模
那么,您知道我们刚才谈到的那些接触点吗?嗯,通过倾向建模还有另一种用途。这是一个统计概念,根据某人所执行的历史操作来考察某人将来执行某项操作的可能性。
它在营销领域有着广泛的应用,包括购买/转化、重复业务、保留和流失。
倾向模型可以很好地处理大量数据,因此将营销接触点数据与网站使用数据以及第一方数据相结合可以根据习惯和人口统计数据创建更丰富的视图。
千禧一代客户与 Z 世代客户的转化方式是否不同?养狗的顾客会做一些养猫的顾客不会做的事情吗?订阅我们的时事通讯是否会增加高价值交易的可能性?倾向建模可以告诉您所有这些以及更多信息。
03. 媒体/营销组合建模 (MMM)
媒体混合建模并不是什么新鲜事,自 20 世纪 50 年代的《广告狂人》时代以来就已存在。新的想法是贝叶斯媒体混合模型,它 允许将其他来源(例如 MTA)、实验和测试的数据输入到模型中,以提高其预测的准确性。
Google 和 Facebook 率先采用了这种方法,发布了lightweight_mmm和Robyn等开源工具,允许公司免费开发自己的下一代贝叶斯 MMM。正如您所期望的那样,两者都是前沿的。
许多公司通过此类模式改进了媒体组合并提高了投资回报率,其中最著名的是Hello Fresh和欧莱雅。
04. 地理测试/实验
地理测试(有时也称为地理实验)绝对是一个新事物,它是一种将线上 (ATL)和线下 (BTL)流结合为直通线 (TTL)方法的方法。
前提很简单。您将市场划分为多个区域,并使用具有相似特征的区域对(匹配的市场)作为营销活动和策略的测试组和对照组。这为您提供了切实的提升数字,以便为更广泛的推广提供信息。
好的部分?由于您将拥有多个区域,因此您可以同时运行多个测试,这将提高测试的节奏,从而更快地影响所有重要的底线。
最好的部分?您可以将这些测试的结果输入到贝叶斯媒体混合模型中,以提高其准确性和场景模型对整个市场的影响。
Wayfair和ASOS都使用它取得了巨大的效果,《哈佛商业评论》将其誉为数字广告衡量的黄金标准。
05. 因果提升/因果推理
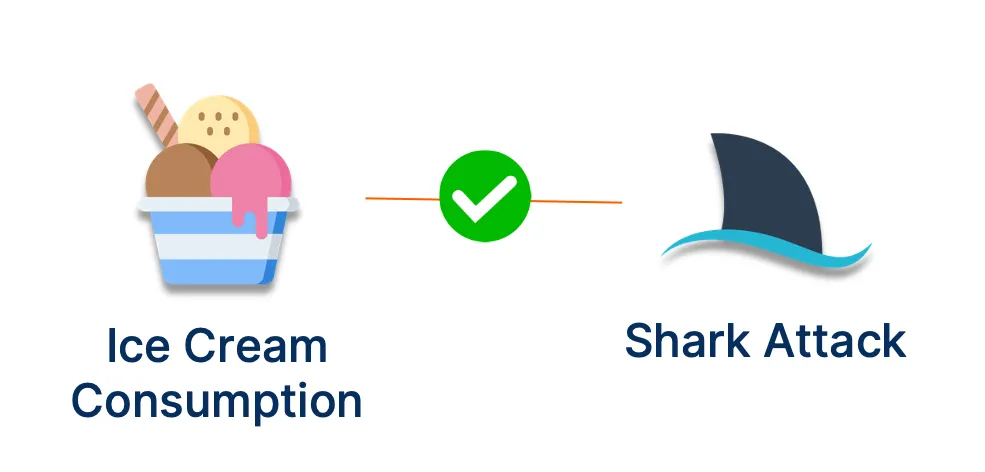
因果推理超越了这一点,它考虑了可能导致相关性的其他因素。
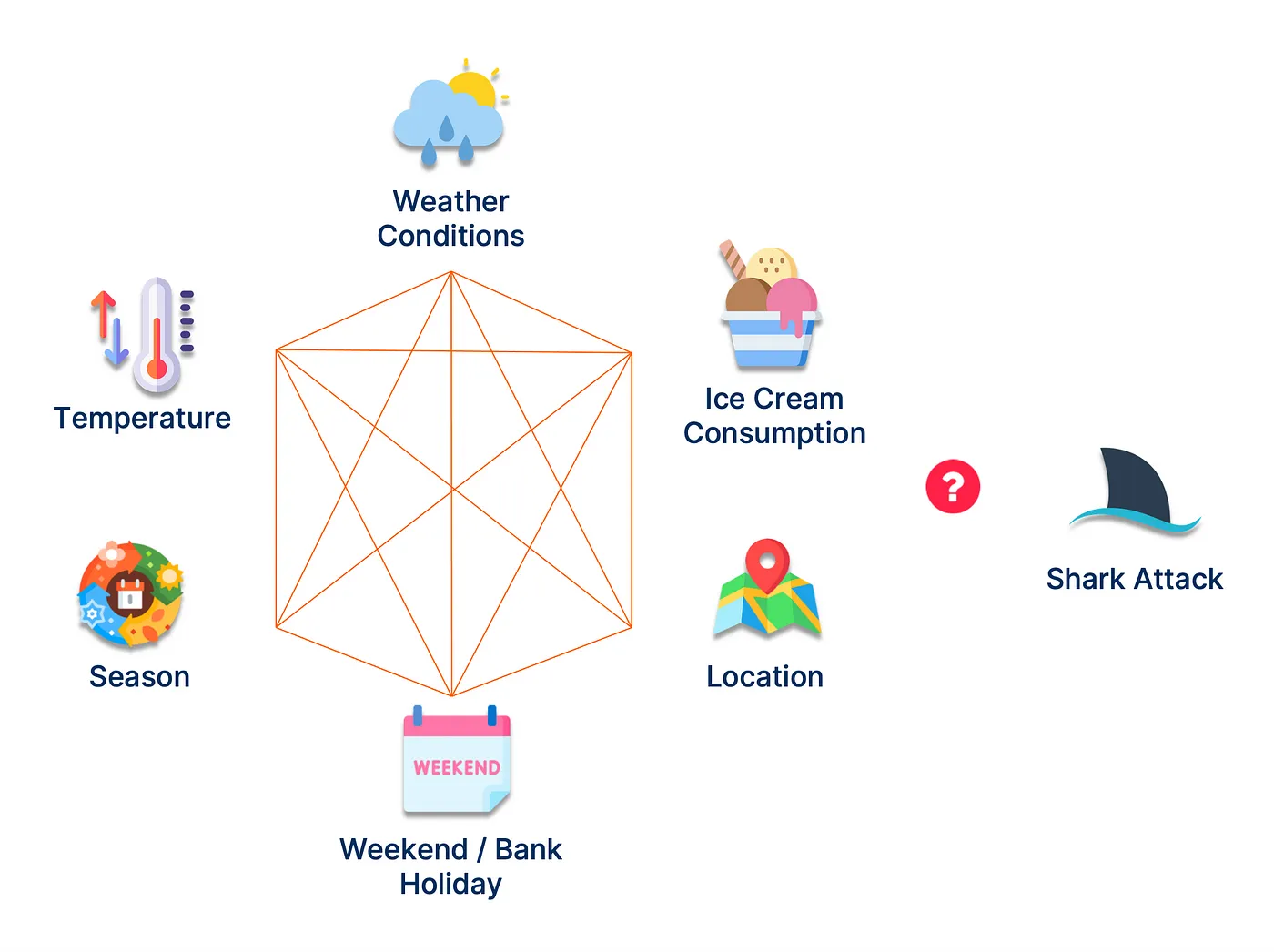
由于大多数其他因素都与冰淇淋消费和鲨鱼袭击相关,因此因果推理可以识别传统方法无法识别的这种关系。
在营销应用方面,它可以提高传统 A/B 或地理测试方法的准确性,深入了解某些事情发生的原因,并衡量其他不可估量的因素,例如奖励计划的影响。
尽管是一项新兴技术,但它仍具有吸引力。Uber 正在使用因果推理来改善用户体验,M & S 正在使用它来衡量和优化他们的 Sparks 奖励计划。
06. 客户群体细分
俗话说,要平等对待人,就要区别对待。有些客户可能会高度参与并欢迎额外的沟通,而其他客户可能不会。有些客户可能会定期消费,有些则可能不会。等等…
细分是一种根据这些因素对客户进行分组的方法,使您能够监控绩效,更重要的是个性化您的内容。
- RFM: RFM 代表新近度、频率和货币价值,它是划分客户群以回答“谁是我最重要的客户?”等问题的一种非常有效的方法。或者“我有失去哪些客户的危险?” 也许更重要的是“我应该瞄准哪些客户?”。如果您没有 RFM 模型,您可能应该停止阅读本文并去制作一个。
- 行为:下一个最大的细分模型是行为。这些使用各种不同的数据点根据相似性将客户分组。现在,如果您有一些数据点(如上面的 RFM 模型),您可以为其编写规则。如果您有几百个数据点,您将需要一个 AI 聚类模型,例如 K-Means,它根据共享特征将客户分组到不同的存储桶中。
- 人口统计:我个人最喜欢的人口统计模型,毫不奇怪,使用客户人口统计数据来划分您的客户群。然而,大多数公司只有几个人口统计数据点可供使用,这就是开放数据的用武之地。如果您了解客户的位置,则可以使用英国人口普查等来源来补充您的数据。英国人口普查尤其是一个包含人口、家庭和经济数据点的详细和精细数据的宝库。缺点是需要做大量的工作才能将其设计成可用的东西,但那是另一天的博客了!
大多数公司已经在对其客户群进行某种形式的细分,但这个游戏肯定是有层次的,这就是其中之一,你投入的精力越多,你就越能获得分析、意想不到的见解和新策略。
它也是一个久经考验的赢家,细分为几乎所有关键营销 KPI 提供了健康的推动。
07. 流失RFM 模型
您知道 RFM 模型吗?好吧,保留其中的数据,因为您的流失模型需要它。流失模型预测客户离开公司轨道的可能性
现在,不存在神奇的摇钱树这样的东西,但是一个精心开发和实施的客户流失模型是下一个最好的东西。获取新客户的成本比保留现有客户高出 5 到 25 倍,而保留率提高 5% 会导致利润增加 25% 到 95%。
大多数公司错误地应对这一挑战,将其视为二元是或否答案(我们称之为人工智能行业中的“分类问题”)。与任何事物一样,事实既不是非黑即白,而是处于灰色地带,这就是为什么最好采用基于概率的贝叶斯流失模型方法。
它使用以前的客户行为来预测流失风险的百分比,而不是简单的是或否。
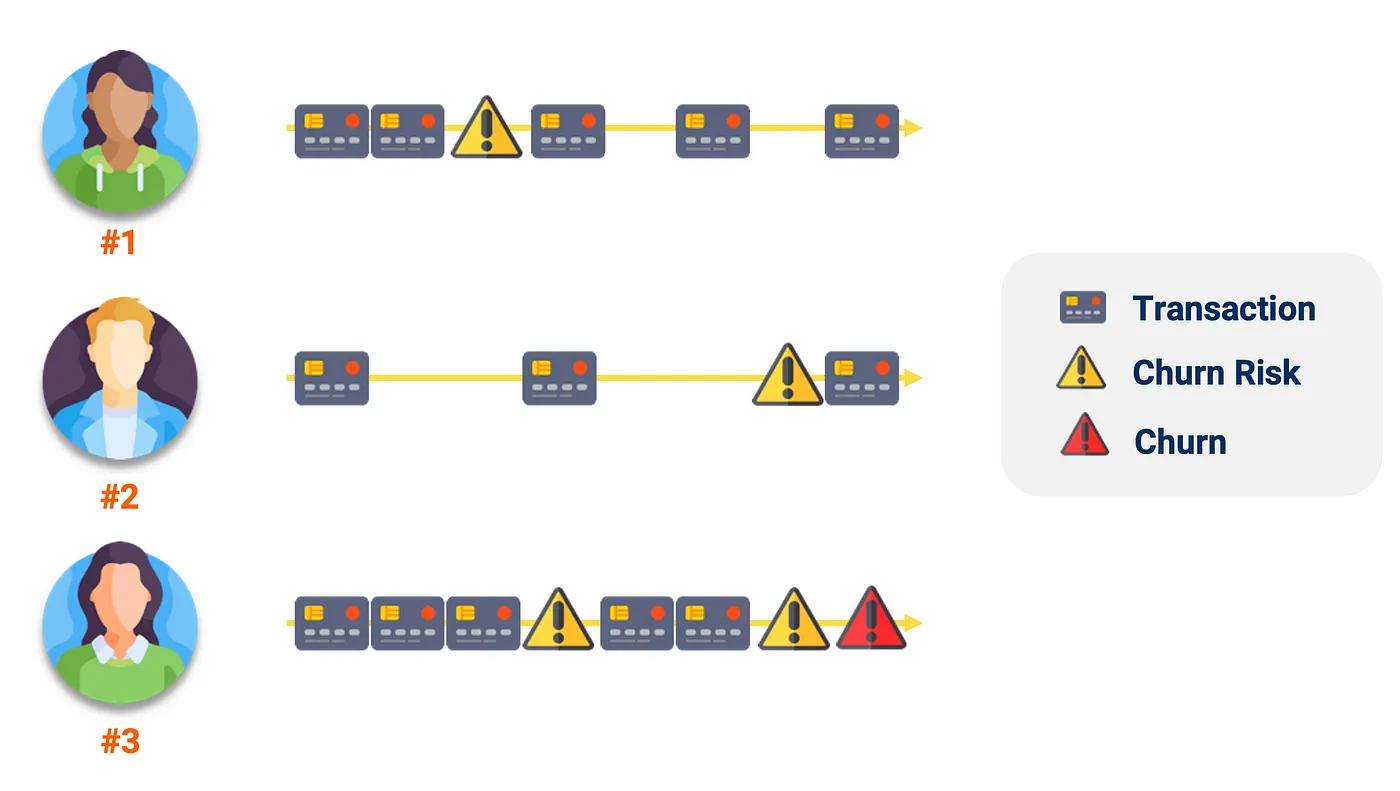
这种方法不仅更快、更准确,而且可以提前发出警告,针对不同程度的客户流失采取不同的干预策略,如果您使用 RFM 等工具对客户群进行了细分,您也可以有效地确定干预行动的优先级。
08. 价格优化
每当我想到定价时,我都会想起蒂姆·哈福德(Tim Harford)撰写的出色的星巴克经济学文章,从那以后,购买咖啡对我来说就不再是一样的了。
设置合适的价格既是一门艺术,也是一门科学。基于人工智能的价格优化是一种游戏规则改变者,使企业能够在保持客户满意度的同时实现利润最大化。
价格优化模型使用历史和实时数据以及见解来预测最佳定价策略。例如,他们可以建议何时提供折扣,旺季期间价格调整多少,或者何时加价以及在不失去客户的情况下加价多少。
09. 推荐系统
除非你一直生活在岩石下,否则你一定听说过亚马逊和 Netflix,这两个科技巨头让推荐引擎闻名。
这些人工智能驱动的系统分析客户数据、偏好和行为,以建议用户更有可能喜欢、欣赏的产品、服务或内容,最重要的是,他们会花费辛苦赚来的钱来购买。
推荐系统主要分为三种类型:
- 基于内容:识别以前购买或参与过的物品并推荐类似的物品(例如,您买了一双手套!想要更多手套吗?)
- 协作过滤:识别类似用户购买或参与过的商品(例如,像您这样的人购买了手套!想要一些手套吗?)
- 混合:正如您所期望的,基于内容的过滤和协作过滤的混合。
哪个最好?与往常一样,这取决于情况,但虽然协作引擎需要做更多的工作,但它们更加细致,通常是提高投资回报率的更安全的选择。一个人只能拥有这么多手套。
就影响而言?事实上,亚马逊是世界第五大公司,其整个业务都建立在推荐系统的基础上,而Netflix 估计他们的推荐系统每年产生 10 亿美元的收入,这一事实告诉了您需要知道的一切。
10. 营销预测
我们无法预测未来,但准确的预测是退而求其次的。
营销预测使企业能够在竞争格局中保持领先地位。它可以准确预测市场趋势和客户行为,并对潜在的困难时期或波涛汹涌的大海发出预警,从而实现更好的决策和明智的干预策略。
但我听到你问,你要怎么做呢?一如既往,有一些选择:
- 时间序列预测:时间序列算法的存在时间与时间本身一样长。几乎。如果您想快速执行某些操作,或者没有或不想包含时间序列本身之外的任何数据,并且可以大规模生成准确的结果,那么它们仍然是一个不错的选择。
- 机器学习预测:如果您确实有一些额外的数据与时间序列相关,那么机器学习可能是一个不错的选择。您还可以在模型中包含时间序列预测及其组件
- 深度学习预测:深度学习预测是一个较新的领域,通过使用长短期记忆 (LSTM) 网络来完成。现场报告表明,它的性能比机器学习预测略好约 10%,但代价是增加了复杂性和处理能力。
总结


![告别“伪创新”与战略悬空: 特斯拉与宝洁都在用的创新战略 6 大核心与落地 3 步法 [附2026全景图解]](https://runwise.co/wp-content/uploads/2023/10/Innovation-Strategy-1290x860-1-300x200.jpg.webp)

![生成式AI商业化7步路线图:[附2026全景图] CDO如何从0构建“AI就绪”的数据架构?](https://runwise.co/wp-content/uploads/2023/11/Fueling-generative-AI-300x157.png.webp)
![创新案例 | [2026图解] 迪卡侬DTC模式:如何靠极致性价比与全渠道体验驱动百亿欧元增长?](https://runwise.co/wp-content/uploads/2023/08/bike-europe-decathlon-germany-breaks-1-biliion-sales-barrier-1-e1692694281340-300x150.jpg)