这篇文章探讨了谁将从生成式人工智能(Generative AI)市场中创造价值。作者分析了生成式AI技术栈,包括计算基础设施、数据、基础模型、微调模型和应用程序,找出了有利可图的领域。基于Transformer架构的大型语言模型(LLM)如GPT-4成为这一领域的基础模型。微调这些通用模型以适应特定任务和行业的需求也带来了商机。此外,基于LLM构建应用程序和编辑工具等产品是另一价值实现途径。总的来说,掌握这些关键要素的企业和新进参与者都有机会在生成式AI市场获利。
Runwise 核心洞察:企业 AI 落地的务实路径
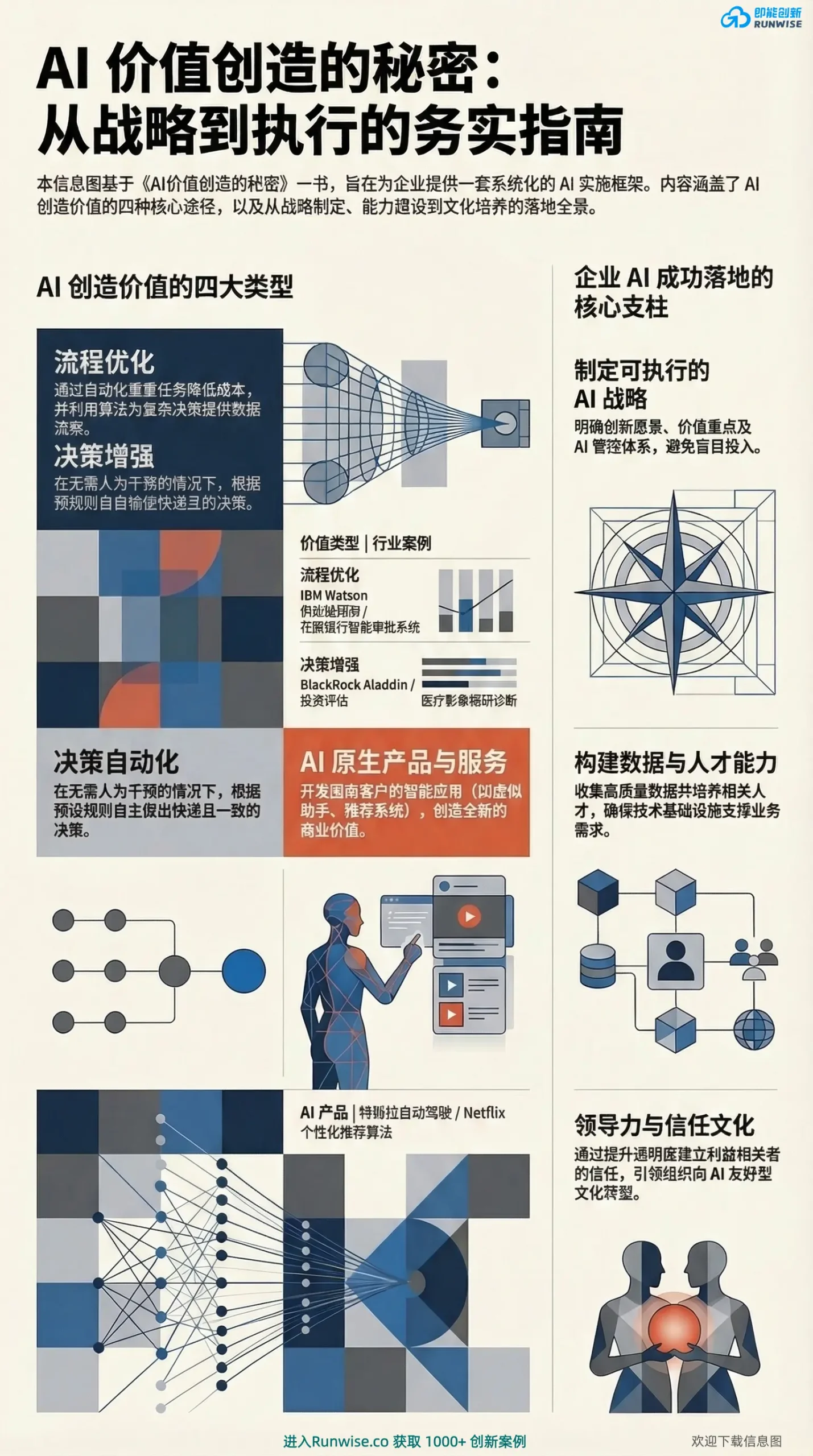
AI 的商业价值并非玄学,而是通过明确的变现路径与坚实的组织支柱,实现从降本增效到业务重塑的全面跨越。
- 明确 4 大价值创造类型:精准定位业务场景,从基础的“流程优化”逐步进阶到“决策增强”、“决策自动化”,最终打造颠覆性的“AI 原生产品与服务”。
- 制定可执行的 AI 战略:明确创新愿景与价值重点,建立严密的 AI 管控体系,坚决避免无目标的盲目技术投入。
- 构建底层数据与人才能力:收集高质量的业务数据,培养懂业务与技术的复合型人才,确保基础设施能真正支撑业务诉求。
- 塑造信任文化与领导力:通过提升算法与决策的透明度,建立利益相关者的信任,引领组织向 AI 友好型文化进行根本性转型。
在 ChatGPT 公开发布后的几个月里,风险投资公司向生成式人工智能初创公司投入了大量资金,企业也加大了对该技术的投入,希望实现工作流程的自动化。这种兴奋是值得的。早期研究表明,生成式人工智能可以显著提高生产率1。这些提高有些来自于增强人力,有些来自于替代人力。
但问题是,谁将从这一爆炸性市场中获取价值,获取价值的决定因素又是什么?为了回答这些问题,我们分析了生成式人工智能堆栈–大致可分为计算基础设施、数据、基础模型、微调模型和应用–以确定差异化的成熟点。虽然文本、图像、音频和视频都有生成式人工智能模型,但我们在讨论中始终使用文本(大型语言模型或 LLM)作为说明背景。
1.解构生成式AI的技术实现
自从 ChatGPT 向公众推出以来,投资激增。风险投资公司正在向生成式人工智能初创公司注入资金,而公司则增加在该技术上的支出以简化其运营。人们对这项技术的热情是有道理的,因为初步研究表明生成式人工智能有潜力大大提高生产力。这些生产率的提高可能源于人力投入的增加和替代。
挥之不去的疑问围绕着谁将抓住这个快速扩张的市场带来的机会以及哪些因素有助于获取这种价值。为了深入研究这些查询,我们深入研究了生成式人工智能堆栈领域,其中包括计算基础设施、数据、基础模型、微调模型和应用程序。我们的目标是找出有潜力脱颖而出的领域。尽管存在适合文本、图像、音频和视频等各种领域的生成式人工智能模型,但我们仍将文本(特别是大型语言模型,即 LLM)作为我们讨论的中心主题。
专业的计算基础设施 – 构成了生成式人工智能技术的基础。该基础设施由高性能 GPU 驱动,用于训练和执行机器学习模型。希望开发新的生成式人工智能模型或服务的公司可以选择投资 GPU 和相关硬件,为本地 LLM 培训和执行建立必要的基础设施。然而,这种方法可能会带来经济负担且不切实际,因为可以通过 Amazon Web Services (AWS)、Google Cloud 和 Microsoft Azure 等领先的云服务提供商轻松访问等效的基础设施。
专有数据 – 生成式人工智能模型的力量来自广泛的互联网规模数据。以 OpenAI 的 GPT-3 背后的训练数据为例,它是 Common Crawl、开放网络存储库以及来自维基百科、在线文学作品和各种其他来源的数据的混合体。 Common Crawl 等数据集的合并表明在模型开发过程中需要吸收来自《纽约时报》和 Reddit 等不同网络来源的数据。此外,基础模型利用从网络爬行活动、合作伙伴关系或雪花市场等平台的数据采购中提取的特定领域信息。尽管模型的训练过程是透明的,但开发人员经常隐瞒有关其数据源来源的复杂细节。尽管如此,研究人员还是利用了即时注入攻击等策略来发现一系列数据源,这些数据源为这些人工智能模型的训练提供了动力。
基础模型 – 是在大量数据集上训练的神经网络,没有针对特定领域或任务(例如生成法律文档或提供技术产品信息)进行特定优化,在人工智能领域发挥着至关重要的作用。这些模型,例如 OpenAI 的 GPT-4 和 Google 的 Gemini,都基于 Vaswani 等人在 2017 年发表的一篇开创性论文中介绍的 Transformer 架构。虽然创建新的基础模型有潜力进入生成人工智能领域,但需要大量数据、计算能力和专业知识等重大障碍限制了高质量大型基础模型的开发。基础语言模型的著名例子包括闭源模型,例如 Meta 的 Llama-2 和阿拉伯联合酋长国技术创新研究所的 Falcon 40B,以及开源替代方案。
RAGs和模型微调 – 基础模型以其在各种语言任务中的多功能性和强大性能而闻名;然而,他们可能并不总是在特定的环境或任务中表现出色。为了提高特定于上下文的任务的性能,可能需要合并特定于域的数据。当将大型语言模型 (LLM) 用于特定目的时,例如帮助用户解决产品的技术问题,有两种可能的方法可供考虑。第一种方法涉及创建一个服务,该服务检索与用户查询相关的相关信息片段,并将该信息附加到提供给基础模型的提示中。例如,在帮助用户解决问题的场景中,这种方法需要开发代码,从产品手册中提取相关细节,与用户的问题紧密结合,并指导法学硕士根据提取的信息生成响应。这种方法通常称为检索增强生成(RAG)。虽然基础模型对其可容纳的提示长度有限制,但它们通常可以处理最多大约 100,000 个单词的提示。与这种方法相关的费用包括基础模型的 API 成本,该成本根据输入提示的大小和 LLM 生成的输出而增加。因此,从产品手册中获取的信息输入到 LLM 中的信息越多,实施成本就越高。
微调模型代表了一种替代策略,但初始计算费用更高。该方法不是简单地向模型提供产品手册中的上下文信息,而是通过利用特定领域的数据来增强基本模型的神经网络。此过程使 ChatGPT 能够处理指令并与用户进行对话。微调过程包括使用针对特定领域定制的数据集重新训练现有的基础模型,例如 Llama 或 GPT-4。
RAG 方法虽然由于模型需要冗长的提示而可能导致较高的 API 成本,但比微调更容易执行。此外,它还消除了在新数据集上重新训练神经网络所需的费用。这意味着 RAG 方法需要较低的设置成本,但在每次用户提出查询时将数据传输到基本模型时会增加可变费用。相反,微调方法虽然最初成本较高,但有望产生优异的结果,并且一旦完成,可以在将来使用,而无需像 RAG 那样为每个问题提供上下文。拥有技术敏锐度的企业可能会发现扩展生成式人工智能工具层的价值,促进微调和 RAG 等选项,无论是用于内部产品开发还是作为向其他企业提供的服务。
LLM 应用. 该结构的最上层包括可以在基础模型或改进模型上构建的应用程序,以满足特定需求。各种初创公司开发了用于生成法律文档 (Evisort)、压缩书籍和电影脚本 (Jumpcut) 或解决技术查询 (Alltius) 的应用程序。这些应用程序遵循典型软件即服务产品的定价模型(按月收费),其额外成本主要与基础模型的云托管和 API 费用相关。
最近,来自科技巨头和各级投资者的大量投资涌入。引入了许多新的基础模型,以及使用独特的数据集进行微调的特定任务模型,以获得竞争优势。此外,许多初创企业正在积极创建基于不同基础模型或定制模型的应用程序。
2.云计算的经验教训
哪些企业能从这些投资中获得最大价值?在过去的几个月里,已经有数十种基础模型面世,其中许多都能提供与更流行的基础模型相媲美的性能。不过,我们认为,基础模型市场很可能会在少数几家公司之间进行整合,就像云服务的大部分市场份额(和价值)被亚马逊、谷歌和微软等公司所占据一样。
大多数云基础设施初创企业失败(或被更大的竞争对手收购)有三个原因,这些原因也适用于生成式人工智能。首先是创建、维持和改进高质量技术基础设施所需的成本和能力。由于训练这些模型所需的数据和计算资源成本非常高昂,这就进一步加剧了 LLM 的情况。这其中就包括 GPU 的成本,而 GPU 的供应量相对于需求量来说是很低的。根据外部估算,仅谷歌 5400 亿参数 PaLM 模型最终训练运行的计算成本就在 900 万到 2300 万美元之间(总训练成本可能是这一数字的数倍)。同样,Meta 在 2023 年和 2024 年对 GPU 的投资估计也将超过 90 亿美元。此外,建立基础模型需要获取海量数据,以及大量的实验和专业知识,所有这些都可能非常昂贵。
其次是需求方的网络效应。随着围绕这些基础设施的生态系统不断壮大,新市场进入者面临的障碍也会随之增加。以 PromptBase 为例,这是一个为 LLM 提供提示信息的在线市场。这里提供最多的提示是 ChatGPT 和流行的图像生成器 Dall-E、Midjourney 和 Stable Diffusion。从技术角度看,新的 LLM 可能很有吸引力,但如果用户有大量在 ChatGPT 中运行良好的提示,而新的 LLM 却没有经过验证的提示,那么他们很可能会坚持使用 ChatGPT。虽然不同 LLM 的底层架构相似,但它们都经过了大量设计,在一种 LLM 上行之有效的提示策略在其他 LLM 上可能并不适用。同时,用户数量是源源不断的礼物: ChatGPT 凭借其庞大的用户群吸引了开发人员在其基础上开发插件。此外,LLM 的使用数据还能形成反馈回路,使模型不断改进。一般来说,最受欢迎的 LLM 会比较小的 LLM 改进得更快,因为它们有更多的用户数据可供使用,而这些改进会带来更多的用户。
第三个因素是规模经济。资源池和需求聚合带来的供应方优势将使拥有庞大客户群的本地语言托管服务的每次查询成本低于初创本地语言托管服务。这些优势包括能够从 GPU 供应商和云服务提供商那里谈判到更优惠的价格。
基于上述原因,尽管新的基础模型会定期发布,但我们预计基础模型市场将围绕几个主要参与者进行整合。
还在为 AI 投资回报率发愁?让专家级智能体为您诊断
不要让您的 AI 战略停留在纸面。立即体验 Runwise 打造的专家级 AI 智能体,精准定位您的业务痛点,感受 10x 战略落地效率的真实威力。
🚀 立即免费体验 Upskill Pro3.构建还是租用?
希望打入生成式人工智能服务市场的公司必须决定是在 GPT-4 等第三方基础模型之上构建应用,还是构建和托管自己的 LLM(要么在开源替代模型之上构建,要么从头开始训练)。在第三方模型上构建应用程序可能会带来安全风险,例如可能会暴露专有数据。使用可信的云计算和 LLM 提供商可以部分降低这种风险,因为它们可以保证客户数据的机密性,不会用于训练和改进其模型。
另一种方法是利用开源 LLM,如 Llama 2 和 Falcon 40B,而不依赖 OpenAI 等第三方提供商。开源模型的吸引力在于,它们为公司提供了对模型完整而透明的访问权限,通常成本更低,而且可以托管在私有云上。不过,开源模型目前在代码生成和数学推理等复杂任务方面的性能落后于 GPT-4。此外,托管此类模型需要内部技术技能和知识,而使用第三方托管的 LLM 则非常简单,只需注册一项服务并使用提供商的应用程序接口即可访问其功能。云提供商已开始越来越多地托管开源模型,并通过 API 提供访问权限,以解决这一问题。
生成式AI技术栈
这些是构成生成式人工智能业务价值的分层组件。
| 层 | 成分 | 示例/推动因素 |
|---|---|---|
|
LLM应用 |
针对特定用例的应用程序 |
• GitHub Copilot(软件开发) • Sudowrite(创意写作) • Jumpcut Media(剧本/书籍摘要) • Alltius(客户支持) |
|
RAG、微调模型、 应用编排 |
用于微调/检索增强生成/应用程序的工具层 |
• Weaviate •Pinecone •LangChain |
|
基础模型 |
大语言模型、多模态模型 |
• OpenAI 的 GPT-4 • Anthropic Claude • Meta 的 Llama-2 •科技创新院Falcon |
|
数据 |
训练模型的数据 |
• Web 爬网数据,例如 Common Crawl •Snowflake市场 •公司内部的专有数据 |
|
计算基础设施 |
云服务 |
•亚马逊云 •微软Azure •谷歌云 |
|
硬件层(用于处理机器学习任务的 GPU) |
• Nvidia(芯片设计) • AMD(芯片设计) •台积电(芯片制造) •英特尔(芯片制造) |
4.特定领域的机遇
LLM 的性能取决于神经网络(即模型)的架构以及训练数据的数量和质量。
变压器模型需要大量数据。高性能的转换器模型–能够生成准确、相关、连贯和无偏见的内容,并且不太可能产生幻觉–能够在超过万亿个标记(LLM 的基本文本单位,通常是一个单词或子单词)的互联网数据和数十亿个参数(机器学习模型的变量,可通过训练进行调整)的规模上运行。最大的 LLM 在各种任务中表现最佳。但是,数据质量和独特性对 LLM 的有效性同样重要,在特定领域的专门任务上,根据特定领域数据训练或微调的模型可以优于大型通用模型。因此,能够获取特定领域大量高质量数据的组织,在为其行业创建专门模型时,可能比其他参与者更具优势。
例如,彭博社利用其对金融数据的访问权,建立了一个专门用于金融任务的模型。BloombergGPT 是一个 500 亿参数的模型,而 ChatGPT-3.5 大约有 4750 亿个参数,但早期研究表明,在一系列基准金融任务上,BloombergGPT 的表现优于 ChatGPT-3.5。4 这两个模型都是在大型数据集上训练的–BloombergGPT 在 7000 亿个代币上训练,ChatGPT-3.5 在 5000 亿个代币上训练。但是,BloombergGPT 52% 以上的训练数据集由精心策划的金融数据源组成,这使它在特定领域的任务上更具优势。尽管如此,最近的一项研究表明,在简单的金融任务(如情感分析)中,GPT-4 在增强提示后的表现优于 BloombergGPT。简而言之,虽然基于特定领域数据建立的模型可以通过更小、更便宜的模型提供强大的性能,但鉴于通用模型在不断发展和完善,对它们的训练不应是一次性的,而需要持续的投资。
其他拥有特定领域数据的行业,如保险、媒体和医疗保健,也可能从专业化的 LLM 中受益。
5.用户界面的重要性
在基础模型(通常称为 GPT 封装)之上构建应用程序的公司面临着一个难题:竞争对手可以通过在相同或更优基础模型之上构建应用程序,轻松复制其应用程序的功能。在缺乏基于模型或数据的差异化的情况下,企业需要在管道末端–机器智能与用户的界面–脱颖而出。
我们认为,这方面的优势在于拥有固定受众的应用程序。以 GitHub Copilot 为例,这是一款由人工智能驱动的生成式代码编写工具。它基于 OpenAI 的 Codex 代码生成器(以及最近的 GPT-4)运行,并通过微软旗下的软件开发平台 GitHub 发布。与开发类似代码生成产品的初创公司相比,使用 GitHub 的 1 亿开发者为它提供了巨大的分发优势。通过对如此庞大的用户群进行分析,GitHub 在改进模式并将其整合到软件开发平台方面也具有明显的优势。(然而,公司在平衡人工智能模型改进与用户隐私问题方面将面临挑战。一个典型的例子是,公众的愤怒促使 Zoom 撤销了对其服务条款的修改,而这一修改本可允许其使用客户内容来训练人工智能模型)。
科技公司会自然而然地倾向于垂直整合,即 LLM 创建者同时也拥有应用程序。谷歌已经将其 LLM 功能整合到了谷歌文档和 Gmail 中,就像微软通过与 OpenAI 合作整合其产品套件一样。
与此同时,在特定领域中没有自己的 LLM 的现有公司可能会发现,在第三方 LLM 的基础上为其现有用户群量身打造应用程序是成功的。它们可以利用自己的最后一英里接入能力,轻松地将新的人工智能功能捆绑到现有产品中,并比竞争对手更快地将这些功能提供给客户。换句话说,如果提供大致相同功能的 LLM 市场规模庞大、竞争激烈,那么那些拥有庞大忠实用户群的应用程序就能利用其在生成式人工智能堆栈顶层的分销优势,从生成式人工智能中获取最大价值。这种优势加上现有公司已经拥有的数据优势,给新进入者带来了挑战。
这对正在制定新一代人工智能战略的管理者有什么影响?如果他们的公司是行业中的现有企业,他们就需要认真思考哪些复杂的特定领域任务可以利用专有数据更好地处理。这种专有优势能让企业为客户提供独特的价值。当一家公司的人工智能服务和产品的功能很容易被竞争对手复制时–要么是因为他们拥有类似的数据,要么是因为通用龙8国际娱乐城可以实现类似的功能–该公司立即向庞大的安装基础推出这些应用并根据海量客户数据进行迭代的能力就必须成为其竞争优势的来源。创业者在创建初创企业时,如果无法获得专有数据或庞大的用户群,就必须认识到自身的劣势,并围绕这些劣势开展工作。他们将不得不在大型通用模型的基础上构建与微调模型相匹配的模型,至少在较简单的特定领域任务上,来构建他们的初始产品和服务。它们必须依靠自身的敏捷性,并利用现有公司的惰性,比强大但缓慢的现有公司更早起步。
6.版权与隐私问题
许多内容创作者都对用于培训法律硕士的版权和知识产权表示担忧。纽约时报》已对 OpenAI 提起诉讼,声称 OpenAI 使用了《纽约时报》的内容来训练其模型并创造替代产品。其他公司、作者和程序员也出于类似原因对 LLM 的所有者提起了诉讼。虽然 OpenAI 认为在受版权保护的内容上训练模型属于版权法的合理使用条款,但它也认识到有必要建立新的内容使用协议模式,并与媒体公司 Axel Springer 签订协议,使用其内容训练 OpenAI 模型。
无论这些诉讼如何解决,有关在其他方创造的知识产权上训练模型的潜在担忧很可能会为生成式人工智能领域的成熟企业带来更大的优势。与较小或较新的实体不同,像谷歌、微软和 Meta 这样的公司有足够的资源在法庭上与版权索赔作斗争,与内容创作者签署许可协议,并对用户使用其模型创建的内容提出的任何版权索赔进行赔偿。

7.同舟共济还是孤军奋战
这对提供生成式人工智能产品和服务的公司意味着什么?那些希望创建新基础模型的公司可能很难在模型性能上与现有公司竞争。超越模型性能的竞争方式是建立生态系统,并为堆栈的每一层提供工具,例如让应用开发人员特别容易在基础模型之上微调或应用 RAG 的工具。如果企业拥有大规模的特定领域数据,那么特定领域的 LLM 将使其有别于通用模型。
想要尝试并最终将生成式人工智能集成到工作流程或产品中的公司,需要尽快明确哪些用例和任务适合进行概念验证。一些相关标准基于对三个问题的回答:
1. 用例是否不受监管?医疗保健和金融服务等高度管制行业中的公司可能会承受巨大的合规和审计负担,使其无法在短周期内计划产品开发和发布。鉴于生成式人工智能的快速进步和变化,快速迭代非常重要,因此多年的产品周期并不是当前生成式人工智能的理想试验台。
2. 错误是否可控?对于生成式人工智能来说,错误或有偏差的输出是不可避免的。在人工智能生成的文本和图像中,有许多 LLM 幻觉以及偏差的例子。同样,企业使用第三方生成式人工智能模型也存在数据保密问题。开发检测和纠正人工智能幻觉的内部能力以及确保 LLM 安全和数据隐私至关重要。
3. 您是否拥有独特的数据和领域知识,以实现和管理微调或 RAG?如果一个应用程序仅仅是一个 GPT 包装,其功能很容易复制,而且该应用程序很可能既不能提供任何竞争优势,也不能解决独特的行业或公司特定挑战。利用专有的第一方数据对于实现价值和建立差异化至关重要。
一旦确定了令人信服的用例,下一个决定就是要考虑供应商的战略以及企业自身的技术成熟度和战略,在此基础上制作或购买模型和/或应用程序。建立一支了解相关技术和评估投资回报率指标的内部团队,对于做出明智的决策至关重要。鉴于这项技术的发展速度如此之快,公司在决定建立自己的模型时,不仅要考虑建立模型的能力,还要考虑继续推进模型以跟上市场步伐的能力。
将 4 大 AI 价值路径转化为企业的真实利润
知道要做流程优化,但不知从何下手?由 Runwise 创始人 Jackie 及资深顾问带队的 【2天 AI 战略共创坊】,手把手帮您梳理核心业务场景,构建高维度 AI 变现路径。无结果不收费,保障落地效果。
📞 专家热线:400 822 8832

扫码预约咨询
打破部门认知壁垒,对齐高管 AI 战略蓝图
看懂了 5 大策略,但高管意见不一、员工抵触推进?由 Runwise 创始人 Jackie 及资深顾问带队的 【2天 AI 战略共创坊】,手把手帮您统一组织认知语言,制定算得清 ROI 的转型蓝图。无结果不收费,保障落地效果。
📞 专家热线:400 822 8832
扫码预约咨询
原文作者
Kartik Hosanagar 是宾夕法尼亚大学沃顿商学院技术与数字商务约翰-C-霍尔(John C. Hower)教授,也是沃顿商学院人工智能中心的创始主任。他是《机器智能人类指南》(A Human’s Guide to Machine Intelligence)一书的作者: 算法如何塑造我们的生活以及我们如何保持控制力》(Viking,2019)和通讯《创造性智能》(Creative Intelligencenormal)的作者。拉马亚-克里希南是卡内基梅隆大学海因茨信息系统与公共政策学院院长,也是该校管理科学与信息系统威廉-库珀和露丝-库珀教授。他是该大学布洛克技术与社会中心(Block Center for Technology and Society)的创始主任,也是国家人工智能咨询委员会人工智能未来小组的主席。


![CEO应对生成式AI的4大蓝图:[2026图解] 如何从“效率工具”走向“模式创新”?](https://runwise.co/wp-content/uploads/2023/03/Generative-AI-Revolution-300x168.jpeg.webp)
![AI 产品增长实战:[2026图解] Gamma用生成式 AI 颠覆 PPT 的三重密码](https://runwise.co/wp-content/uploads/2023/09/gamma-app-300x150.jpeg.webp)

![创新案例 | [2026图解] 蔚来DTC增长3大策略:如何以车主社区口碑驱动销量爆发?](https://runwise.co/wp-content/uploads/2023/09/Nio-DTC-growth-300x169.jpg.webp)